HiFaceGAN 논문 리뷰
HiFaceGAN은 저화질의 얼굴 이미지를 고화질로 복원하는 모델로, papers with code의 얼굴 고화질 복원 모델 3가지 부문의 SOTA 모델입니다. Github 논문 -> HiFaceGAN: Face Renovation via Collaborative Suppression and Replenishment
3줄 요약
- 얼굴의 전체적인 형태 특징과 이미지 품질이 저하된 방법을 모르는 “dual-blind” 상태에서도 고화질 얼굴 이미지로 복원하는 “Face Renovation”이 실제 저화질 이미지 복원을 위하여 필요함.
- 본 논문에서는 여러 개의 CSR (Collaborative Suppression & Replenishment) 모듈들을 적용하여 실제와 같은 Face Renovation이 가능한 HiFaceGAN 모델을 제안함.
- 해당 모델을 사용해 인공적으로 생성된 데이터와 실제 저화질 데이터 (real-world)에서 눈에 띄는 성능의 향상을 보였음.
Introduction
실제 저화질 얼굴 이미지는 여러 다른 종류들로 이루어진 품질 저하들을 통해서 저화질으로 변한다. 이를 복원하기 위하여 수많은 종래 연구들이 있었는데, 기존 연구들은 특정한 한 가지의 품질 저하에 대해서만 복원한 연구가 많다. 이러한 연구들은 여러 종류로 품질 저하가 이루어진 실제 상황에서의 성능이 좋지 않았다. 대표적인 예시가 아래의 1927년 솔베이 회의 사진을 복원한 예시로 HiFaceGAN을 제외한 다른 모델들은 이러한 실제 저화질 이미지에 대한 성능이 떨어짐을 볼 수 있다.

이러한 문제로 특정한 품질 저하가 아닌 알 수 없는 품질 저하를 복원하는 ‘single-blind’ 이미지 복원에 대한 연구도 이루어졌다. 이러한 연구에서는 주로 얼굴의 landmark, parsing map, component heatmap 등을 이용하여 얼굴의 구조적 특징을 파악하여 복원하는 방식을 사용한다. 하지만 이러한 특징들을 파악할 수 없는 경우 얼굴의 복원이 불가능하다는 단점이 있다. 또한, 잘못된 얼굴의 구조적 특징을 잡으면 복원된 얼굴의 품질이 급격하게 떨어진다는 단점도 있다.
그렇기에 이 논문에서는, 이미지 품질 저하의 종류 및 세기와 얼굴의 구조적 특징을 모르는 “dual-blind” 상태의 이미지 복원에 초점을 맞추며, 이를 “Face Renovation” (이하 FR)로 부르기로 한다. 그리고 FR을 수행하기 위한 HiFaceGAN을 제안한다. HiFaceGAN은 여러 개의 CSR 모듈을 적용한 프레임워크이다. CSR 모듈은 유의미한 feature를 검출하고, 그 feature들을 통해 복원하는 이미지에 보충할 수 있다. HiFaceGAN은 FFHQ를 이용한 인공 데이터셋과 실제 저화질 이미지들에서 좋은 성능을 보여준다.
HiFaceGAN
Network 구조
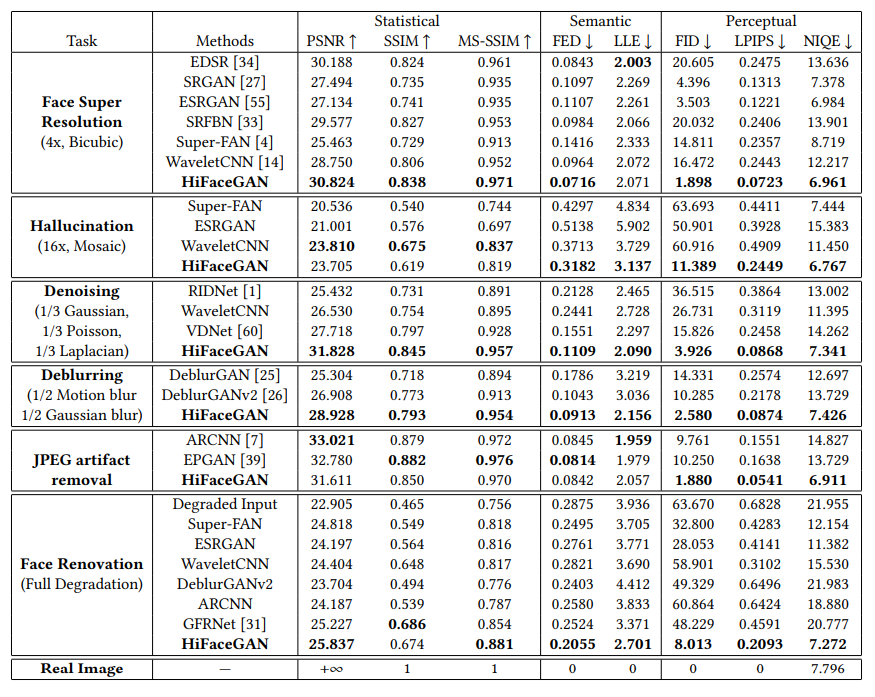
 HiFaceGAN에서는 여러 개의 CSR 유닛들을 이용하며, 각 유닛들이 각기 다른 종류의 유의미한 feature를 구할 수 있다. 각 유의미한 feature들을 계층적으로 존재하며, 먼저 저화질의 input에서 각 feature들을 뽑아낸다. 그리고 각기 다른 보충 레이어를 통과하면서, 뽑아낸 feature들의 역순으로 해당 의미를 반영하여 학습한다. 여기서 각 유의미한 feature들의 종류를 모델이 직접 학습하도록 하여 어떠한 순서와 방식으로 품질 저하가 일어났든 그것을 학습할 수 있다.
HiFaceGAN에서는 여러 개의 CSR 유닛들을 이용하며, 각 유닛들이 각기 다른 종류의 유의미한 feature를 구할 수 있다. 각 유의미한 feature들을 계층적으로 존재하며, 먼저 저화질의 input에서 각 feature들을 뽑아낸다. 그리고 각기 다른 보충 레이어를 통과하면서, 뽑아낸 feature들의 역순으로 해당 의미를 반영하여 학습한다. 여기서 각 유의미한 feature들의 종류를 모델이 직접 학습하도록 하여 어떠한 순서와 방식으로 품질 저하가 일어났든 그것을 학습할 수 있다.
Suppression 모듈
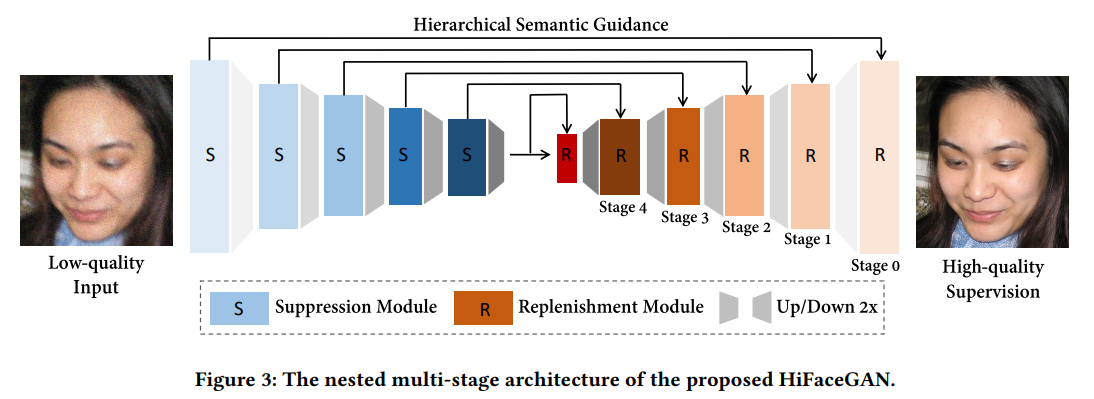
실제 저화질 이미지에서는 여러 종류의 품질 저하가 일어나서, CNN 레이어에서는 어떤 것이 노이즈이고 실제 이미지인지 구분하기 힘들다. 일반적인 CNN 레이어는 이미지 전체에 대하여 똑같은 커널 가중치를 사용한다. 이러면 이미지의 노이즈 부분을 kernel에 통과시킬 때와 컨텐츠를 통과시킬 때 똑같은 가중치가 사용되기 때문에, 노이즈와 이미지 컨텐츠를 구분할 수 없어 성능이 좋지 못하다. 이를 해결하기 위하여 유의미한 정보가 있는 부분에는 다른 kernel 가중치를 사용하는 content-adaptive 필터를 적용한다. 이를 가능하게 하는 구조는 아래 사진과 같다.  해당 구조에서 \(\mathcal{G}\)는 여러개의 레이어로 이루어진 작은 퍼셉트론으로, 의미있는 feature를 구분하기 위해 학습한다. 또한, \(\mathcal{D}\)는 sigmoid나 tanh와 같은 비선형적 activation 함수이다. 이미지 convolution을 수행할 때 각 kernel에 대하여 \(\mathcal{G}\)를 학습하여 유의미한 feature를 뽑아내는 퍼셉트론을 훈련하고, 이를 각 가중치와 곱하여 convolution을 수행하는 구조이다. 이를 통해 유의미한 feature를 골라내는 능력을 최대화 한다.
해당 구조에서 \(\mathcal{G}\)는 여러개의 레이어로 이루어진 작은 퍼셉트론으로, 의미있는 feature를 구분하기 위해 학습한다. 또한, \(\mathcal{D}\)는 sigmoid나 tanh와 같은 비선형적 activation 함수이다. 이미지 convolution을 수행할 때 각 kernel에 대하여 \(\mathcal{G}\)를 학습하여 유의미한 feature를 뽑아내는 퍼셉트론을 훈련하고, 이를 각 가중치와 곱하여 convolution을 수행하는 구조이다. 이를 통해 유의미한 feature를 골라내는 능력을 최대화 한다.
Replenishment 모듈
앞서 Suppresion 모듈을 통해서 유의미한 feature들을 뽑는 데에 성공했으니, 이제 그것을 통해 SR을 수행할 수 있다. SPADE를 통해서 semantic-guided 생성을 수행할 수 있다. 아래는 SPADE를 통하여, 의미적으로 분류해놓은 map을 가지고 풍경 사진을 생성한 사진이다. 
HiFaceGAN에서는 Replenishment 모듈에 이 SPADE를 활용하여 Suppression 모듈에서 추출한 semantic feature를 적용하여 얼굴을 생성한다. 자세하게, 여러 계층적인 SPADE 블록을 포함하고 있으며 각 블록들은 그 이전의 블록의 출력과 Suppresion 모듈에서 구했던 semantic feature를 받아들여 출력을 내놓는다. 이러한 방법으로 HiFaceGAN은 명시적인 얼굴 구조 정보 없이도 자동으로 전체적인 얼굴의 구조를 파악하여 반영할 수 있다.
Loss Functions
많은 이미지 복원 연구들이 loss function으로 MSE를 사용하는데 이는 blurry한 결과를 가져온다. 실제 복원 결과는 높은 realness와 시각적 품질을 가져야하며, 이 경우 작은 불일치성은 용인할 수 있다. 이를 위해 HiFaceGAN은 adversarial loss \(\mathcal{L}_{GAN}\)을 사용한 적대적 훈련 방법을 채택한다. 해당 adversarial loss는 LSGAN을 기반으로 채택하였으며 아래와 같다. \(\mathcal{L}_{GAN} = E[||\log{(D(I_{gt}))-1}||_2^2] + E[||\log{(D(I_{gen}))}||_2^2]\) 또한, 다른 크기의 feature들을 조정하는 loss \(\mathcal{L}_{FM}\)과 perceptual loss \(\mathcal{L}_{perc}\) 역시 사용한다. \(\mathcal{L}_{FM}\)의 수식은 다음과 같으며, \(\phi\)는 이 연구의 multi-scale Discriminator에서 참조했다. \(\mathcal{L}(\phi) = \sum_{i=1}^L{\frac{1}{H_iW_iC_i}}||\phi_i(I_{gt})=\phi_i(I_{gen})||_2^2\) 또한, perceptual loss는 pretrained한 VGG-19 네트워크를 사용한다. 결론적으로 최종적인 loss는 아래와 같다. \(\mathcal{L}_{recon} = \mathcal{L}_{GAN} + \lambda_{FM}\mathcal{L}_{FM} + \lambda_{perc}\mathcal{L}_{perc}\)
Discussion
HiFaceGAN의 메커니즘
 위의 그림에서 HiFaceGAN이 어떻게 실제로 작동하는 지 볼 수 있다. 각 Suppression 모듈에서 facial landmark, 텍스쳐, 그림자나 반사 등을 학습하고, 그것들을 합치면 점점 완전한 사진이 되는 것을 볼 수 있다. 이와 같이 저화질 이미지에서 각 semantic feature들을 학습한다. 그리고 각 feature들이 계층적인 Replenishment 모듈로 각각 투입된다. 이 과정에서 자동으로 facial landmark, 텍스쳐 등을 학습하여 알 수 있는 것이다.
위의 그림에서 HiFaceGAN이 어떻게 실제로 작동하는 지 볼 수 있다. 각 Suppression 모듈에서 facial landmark, 텍스쳐, 그림자나 반사 등을 학습하고, 그것들을 합치면 점점 완전한 사진이 되는 것을 볼 수 있다. 이와 같이 저화질 이미지에서 각 semantic feature들을 학습한다. 그리고 각 feature들이 계층적인 Replenishment 모듈로 각각 투입된다. 이 과정에서 자동으로 facial landmark, 텍스쳐 등을 학습하여 알 수 있는 것이다.
Blind 얼굴 복원과 비교
기존 Single-Blind 얼굴 복원을 하기 위해, 기존 SOTA 모델인 GFRNet과 HiFaceGAN을 비교했다. GFRNet이 더 많은 노이즈와 더 낮은 의미적 디테일을 보이는 것을 알 수 있었다. 또한, GFRNet과는 다르게 얼굴을 제외한 배경 역시 더욱 잘 복원하는 모습을 보였다. 이를 통해 “dual-blind”를 사용한 방식이 얼굴이 아닌 이미지에게도 유효할 수 있다는 가능성을 보였다.
Experiments